
Real-Time Filipino Sign Language Recognition with CNN-LSTM
A CNN-LSTM model that recognizes 15 Filipino Sign Language gestures from webcam video in real time. MediaPipe landmark extraction, custom dataset of 216 sequences per gesture, browser deployment via TensorFlow.js.
Problem
There's no widely available Filipino Sign Language recognition system. The Filipino deaf community has limited access to real-time translation tools, and FSL is structurally different from ASL — existing ASL recognition models don't transfer. Building one from scratch meant creating the dataset, training the model, and deploying it to run in a browser with no server dependency.
Why it's hard
No existing FSL dataset. Unlike ASL, which has established datasets (MNIST Sign Language, etc.), Filipino Sign Language had no readily available landmark dataset. Every gesture — both static alphabet signs and dynamic word-level signs — had to be recorded, preprocessed into 30-frame sequences, and labeled from scratch.
Dynamic gestures need temporal modeling. Static signs (individual letters) can be classified from a single frame. Dynamic signs (words like "kamusta," "magandang umaga") are sequences of hand movements over time. A single-frame CNN can't distinguish between the start of one gesture and the middle of another. The model needs to understand temporal patterns across multiple frames.
Real-time inference in a browser. The system needs to run fast enough that translation feels instant on a webcam feed. That means the model has to be small enough for TensorFlow.js, and the preprocessing pipeline (MediaPipe to keypoints to model input) has to complete within a single frame interval.
258-dimensional input from a noisy source. MediaPipe Holistic extracts pose landmarks (33 x 4 = 132 dims), left hand (21 x 3 = 63 dims), and right hand (21 x 3 = 63 dims) — 258 dimensions per frame. When hands are partially occluded or leave the frame, MediaPipe returns zeros. The model has to handle these gaps without collapsing.
Architecture
The pipeline runs in four stages:
- Capture — OpenCV reads webcam frames.
- Extract — MediaPipe Holistic detects pose, left hand, and right hand landmarks. Each frame becomes a 258-dimensional vector.
- Buffer — A sliding window holds the last 30 frames. The model only predicts when the window is full.
- Predict — The Conv1D-LSTM classifies the 30-frame sequence into one of 15 gestures. Predictions above a 0.5 confidence threshold are displayed; a 10-frame stability check prevents flickering between gestures.
The 15 gestures
Static (alphabet): F, L, N, O, P
Dynamic (words): ako (I/me), bakit (why), hi, hindi (no), ikaw (you), kamusta (how are you), maganda (beautiful), magandang umaga (good morning), oo (yes), salamat (thank you)
The model
The Conv1D layer before the LSTM stack captures local temporal patterns (short finger movements within 2-3 frames). The LSTM layers then model longer-range sequential dependencies across the full 30-frame window.
Training: 216 sequences per gesture, 2000 epochs, Adam optimizer, categorical crossentropy, 90/10 train/test split.

Key decisions
MediaPipe landmarks over raw pixel input. Processing full video frames would require a much larger model and more training data. MediaPipe reduces each frame from millions of pixels to 258 coordinates — a 4+ order-of-magnitude dimensionality reduction. The model only needs to learn gesture patterns in landmark space, not visual features.
Conv1D before LSTM. A pure LSTM baseline missed subtle finger movements that happen within 2-3 frame windows. Adding a 1D convolution before the LSTM stack captures short-range temporal patterns before the LSTMs handle the full sequence.
TensorFlow.js for browser deployment. Server-side inference would add latency and require hosting. Converting the Keras model to TensorFlow.js (~950 KB shard) means the model runs entirely client-side. No server round-trip, no API key, works on any device with a camera and a browser.
30-frame fixed window. FSL words typically complete within 1-2 seconds. At typical webcam framerates, 30 frames captures enough temporal context for dynamic gestures while keeping the model input small enough for real-time inference.
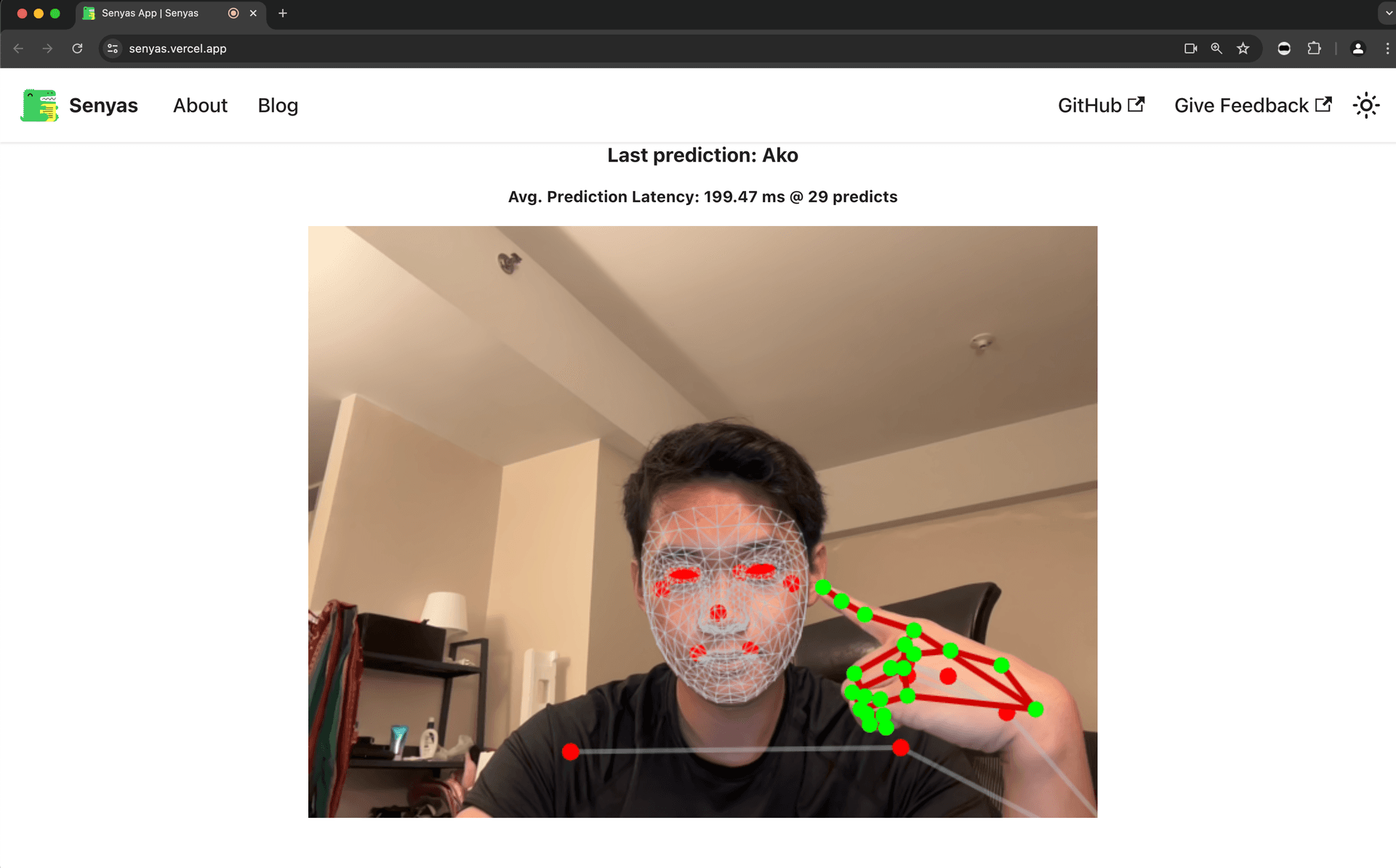
What didn't work
The accuracy gap between test and real-world. The model hits 92% on the held-out test set but drops to 86% on live webcam input. The test set comes from the same recording sessions as the training data — same lighting, same background, same signer. Real-world conditions introduce variation the model hasn't seen. This is a data diversity problem, not a model capacity problem.
Gesture boundaries are ambiguous. The 0.5 confidence threshold and 10-frame stability check are heuristics to prevent flickering between gestures. They work most of the time, but the system still misclassifies during transitions between signs. A proper gesture segmentation model would handle this better than a fixed sliding window.
Single-signer training data. The dataset was recorded by a small number of signers. Different people have different hand sizes, speeds, and signing styles. The model likely overfits to the training signers' specific movements rather than learning the abstract gesture pattern.
What I'd change
Record from more signers. The single biggest improvement would be training data diversity. Five signers instead of one or two would probably close most of the 92% to 86% gap.
Augment in landmark space. Instead of augmenting video frames (rotation, scaling), augment the extracted keypoints directly — small random offsets to hand positions, slight speed variations in the temporal axis. This is cheaper than re-recording and targets the actual model input.
Explore attention over LSTM. Transformer-style attention could replace the LSTM stack for temporal modeling. The attention mechanism might better handle variable-length gestures and transitions.
Key lessons
Dimensionality reduction before deep learning. MediaPipe did the heavy lifting. Reducing video to 258-dim landmark vectors made a small model trainable on a small dataset. Without it, this project would have required orders of magnitude more data and compute.
Test accuracy overestimates real-world performance. The 6-point gap between test (92%) and real-world (86%) came entirely from distribution shift — same model, different conditions. Evaluating on data from the same recording sessions as training is not a reliable indicator of production performance.
- Recognized FSL gestures
- 15
- Test set accuracy
- 92%
- Real-world accuracy (live webcam)
- 86%
- TensorFlow.js model size
- ~950 KB